
– efficient & ready-to-execute for slow loading sheets in Pyhton / Google Colab
Goal of this tutorial: efficient and simple removal of duplicates from spreadsheet data!
In this tutorial and video, I show you how to remove duplicates such as in this data. Fast and actionable. Specially for bigger data where loading the sheet or excel files of data are slow.
Video Tutorial of this topic, complementing this blog, is available here:
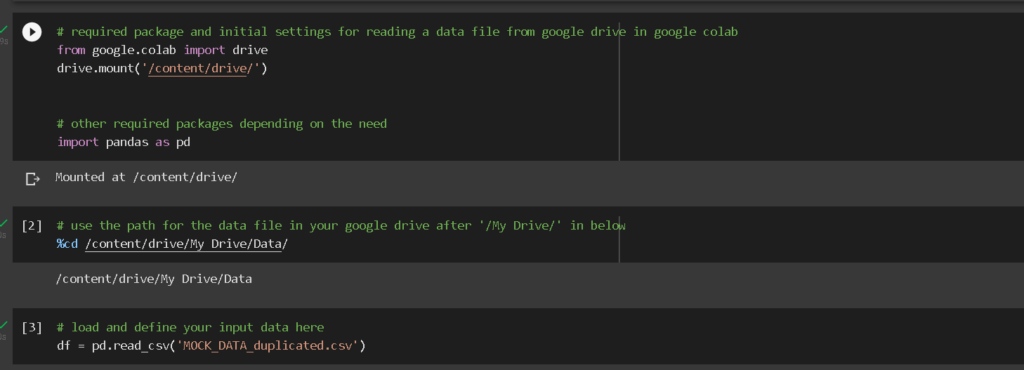
Step1: Initial Settings
This first block run the needed libraries and connect the code to google sheets, where input data exist in this example.
- For reading data from google sheets refer to this tutorial: https://winswithdata.com/?p=12
- For reading data from google drive refer to this tutorial: https://winswithdata.com/?p=1
Connect this colab code to your google drive
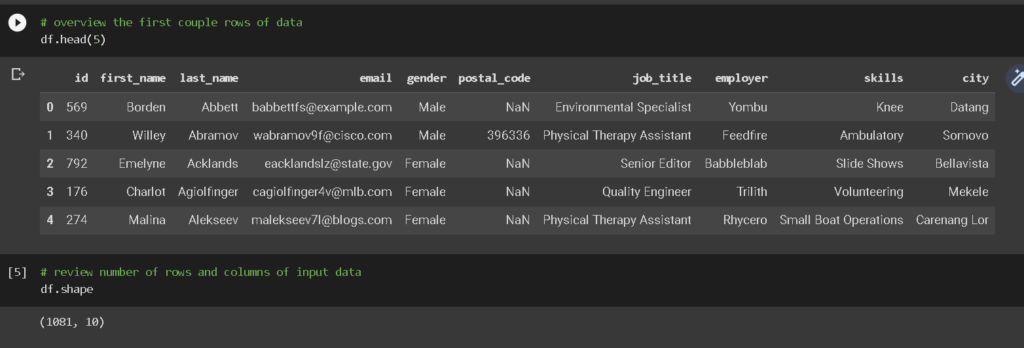
Let’s take a look at data and some duplication examples in it.
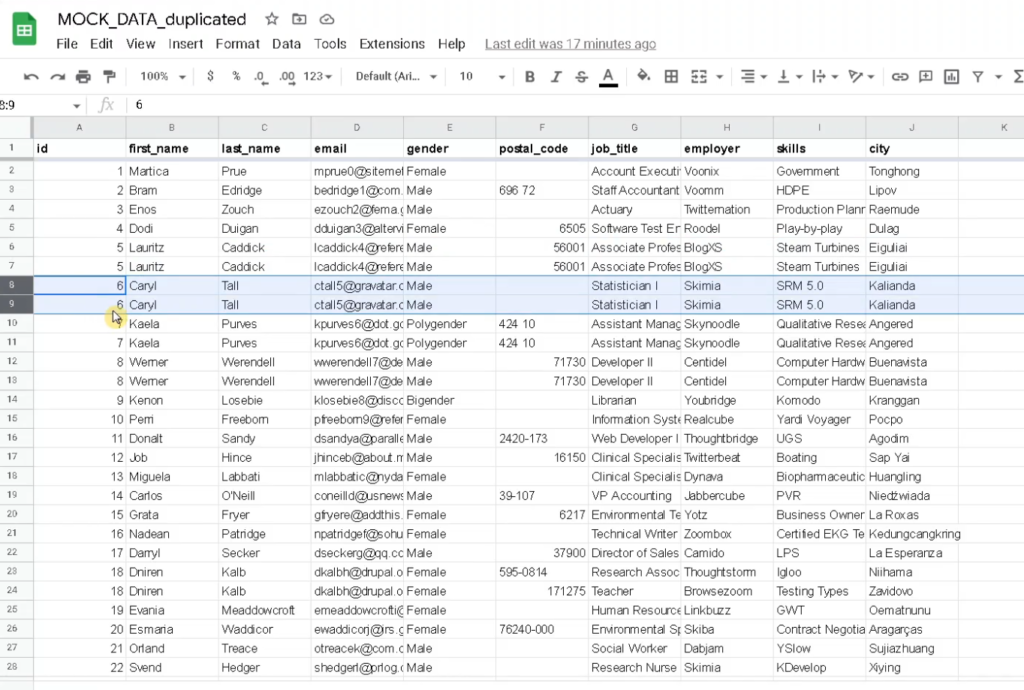
Example of duplication in the data.
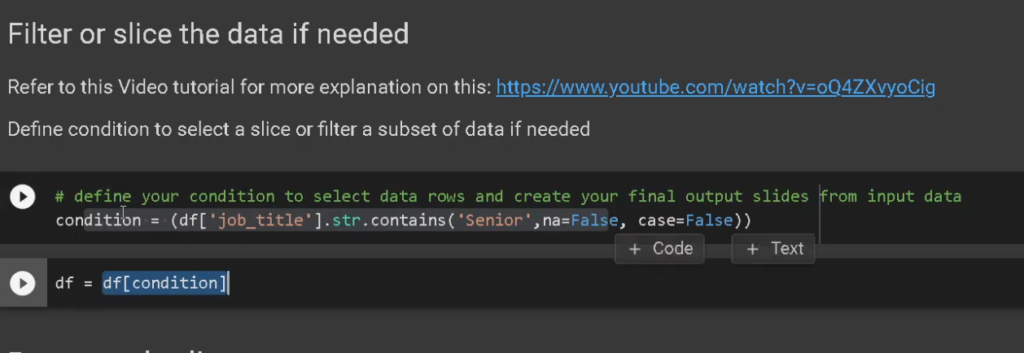
Filter or slice the data if needed
Step2: if needed filter or slice the data to focus on the sample you want. The referred video tutorial link provide more information on this.
- Refer to this tutorial for more explanation on filtering data: https://winswithdata.com/?p=34
Define condition to select a slice or filter a subset of data if needed
Removing Duplicates
Step3: Remove duplicates in scenario 1. Duplicates based on all columns
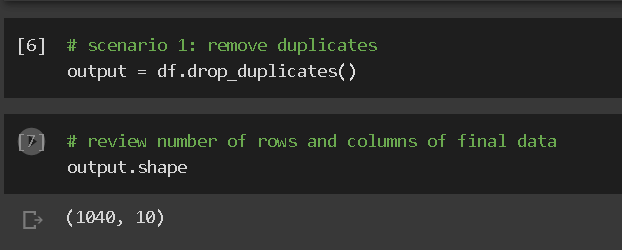
Remove duplicated based on multiple selected data columns in python
Step4: remove duplicates based on subset of columns, not all. Let’s have a look at all columns to choose first.
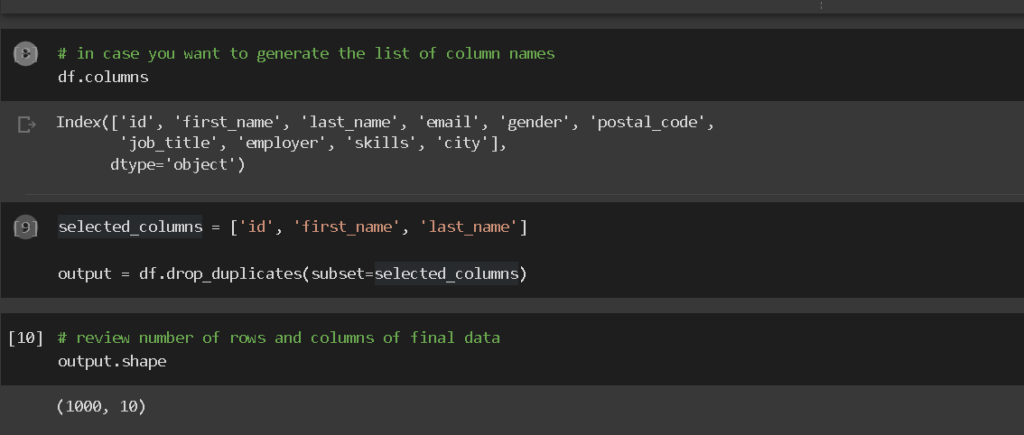
In this example, if there are repeated information based on first name, and last name, and id, delete the repeated ones.
Step5: last step, saving the data in google sheets!
Related links for this video:
- code script template solution for this video: https://colab.research.google.com/drive/15LjeU-bRM59KSKPWfNYeq9Vui48rBDlt?usp=sharing
- The code is written in Google Colab environment.
- Subscribe to learn move about Colab, Python and Data & more!
- sample data used in this video: https://docs.google.com/spreadsheets/d/1H2-227MHQLe4o6kmASIYaq4F9atYYluPsSXJO8sjTDU/edit?usp=sharing